

Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It’s a fully managed, multi-region, multi-active, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and can support peaks of more than 20 million requests per second. It’s relied on across industries and verticals to back mission-critical applications. As such, DynamoDB is designed for efficient online transaction processing (OLTP) workloads; however, what if you want to also perform ad hoc online analytical processing (OLAP) queries? The data in OLTP systems is the proverbial gold mine for analytics. Recently, DynamoDB announced a feature you can use to export point-in-time recovery (PITR) backups to Amazon Simple Storage Service (Amazon S3), making your DynamoDB table data easily accessible in your Amazon S3 bucket at the click of a button. For more information, see Exporting DynamoDB table data to Amazon S3.
After you export your data to Amazon S3, you can use Amazon Athena, Amazon Redshift, Amazon SageMaker, or any other big data tools to extract rich analytical insights. Although you can query the data directly in the DynamoDB JSON or Amazon Ion format, we find that for larger datasets, converting the exported output into Apache Parquet—a popular, high-performant columnar data format—translates into faster queries and cost savings. Like DynamoDB itself, this feature functions at any scale with no impact on the performance or availability of production applications. You can export data from your DynamoDB PITR backup at any point in time in the last 35 days at per-second granularity, and the exported dataset can be delivered to an Amazon S3 bucket in any AWS Region or account. Previously, integrating and analyzing table data in DynamoDB required custom configurations by using tools such as AWS Data Pipeline or Amazon EMR. These tools perform a table scan and export the data to Amazon S3 or a data warehouse for analytics, thereby consuming table read capacity. In addition, these scan-based solutions require expertise in big-data tools, infrastructure deployment, capacity management, and maintenance.
In this post, we show how to use the DynamoDB-to-Amazon S3 data export feature, convert the exported data into Apache Parquet with AWS Glue, and query it via Amazon Athena with standard SQL.
Solution overview
The walkthrough in this post shows you how to:
- Enable point-in-time recovery (PITR) on a DynamoDB table.
- Initiate a data export.
- View the dataset in Amazon S3.
- Transform the exported data into Apache Parquet by using AWS Glue.
- Build and craft SQL queries with Athena.
This post assumes that you’re working with an AWS Identity and Access Management (IAM) role that can access DynamoDB, Amazon S3, AWS Glue, and Athena. If you don’t have an IAM role to access these resources, it’s recommended that you work with your AWS account administrator. The AWS usage in this post consumes resources beyond the Free Tier, so you will incur associated costs by implementing this walkthrough. It’s recommended that you remove resources after you complete the walkthrough.
The following diagram illustrates this post’s solution architecture.

We start by exporting Amazon DynamoDB data to Amazon S3 in DynamoDB JSON format [1]. Once the export is complete, we configure an AWS Glue crawler to detect the schema from the exported dataset [2] and populate the AWS Glue Data Catalog [3]. Next, we run an AWS Glue ETL job to convert the data into Apache Parquet [4], and store the data in S3 [5]. Amazon Athena uses the AWS Glue Catalog to determine which files it must read from Amazon S3 and then executes the query [6].
About the process of exporting data from DynamoDB to Amazon S3
Let’s first walk through the process of exporting a DynamoDB table to Amazon S3. For this post, we have a DynamoDB table populated with data from the Amazon Customer Reviews Dataset. This data is a collection of reviews written by users over a 10-year period on Amazon.com. DynamoDB is a good service for serving a review catalog like this because it can scale to virtually unlimited throughput and storage based on user traffic. This is an OLTP workload with well-defined access patterns (create and retrieve product reviews).
For this post, our data is structured on the table by using ProductID as the partition key and ReviewID as the sort key (for more information about key selection, see Choosing the Right DynamoDB Partition Key). With this key design, the application can create and retrieve reviews related to products quickly and efficiently. The following screenshot shows the data model of this table, which we created by using NoSQL Workbench.
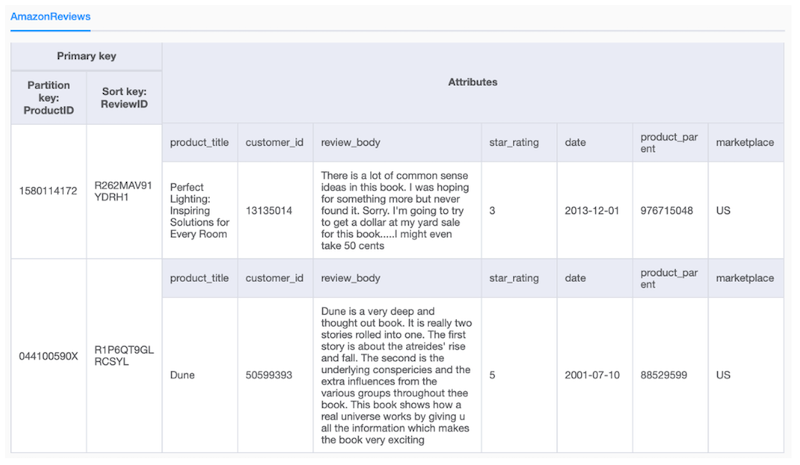
The data model for this review catalog works well for the OLTP requests from the application, but a common request is to support analytical queries. For this table, imagine that a marketing team wants to find the product that received the most reviews, or perhaps they want to identify which customers posted the most reviews. These are basic analytic queries, but the table isn’t organized to handle these queries so it requires a full table scan and an application-side comparison to retrieve the information. Although you can model the data to create real-time aggregate counts indexed with a sharded global secondary index, this would require planning and complexity. In this example, the marketing team likely has tens or hundreds of analytical queries, and some of them are built on the results of previous queries. Designing a non-relational data model to fit many analytical queries is neither reasonable nor cost-effective. Analytical queries don’t require high throughput, many concurrent users, or consistent low latency, so these queries also don’t benefit from a service like DynamoDB. However, if the DynamoDB dataset is easily accessible in Amazon S3, you can analyze data directly with services such as Athena or Amazon Redshift by using standard SQL.
Previously, exporting a table to Amazon S3 required infrastructure management, custom scripts and solutions, and capacity planning to ensure sufficient read capacity units to perform a full table scan. Now, you can export your DynamoDB PITR backups dataset to your Amazon S3 bucket at the click of a button. The export feature uses the DynamoDB native PITR feature as the export data source, and it doesn’t consume read capacity and has zero impact on table performance and availability. Calculating cost is simplified because the export cost is per GB of exported data. The beauty of the export feature is that it makes it simple for you to export data to Amazon S3, where analytical queries are straightforward by using tools such as Athena.
Enable PITR on a DynamoDB table
The export feature relies on the ability of DynamoDB to continuously back up your data using PITR. It enables you to restore from your continuous backup to a new table and to export your backup data to Amazon S3 at any point in time in the last 35 days. Get started by enabling PITR on a DynamoDB table, which you can do via the API, AWS Command Line Interface (AWS CLI), or DynamoDB console. In our case, we have used the DynamoDB console to enable PITR, as shown in the following screenshot.

Initiate a data export from DynamoDB to Amazon S3
DynamoDB data is exported to Amazon S3 and saved as either compressed DynamoDB JSON or Amazon Ion. Once your data is available in your Amazon S3 bucket, you can start analyzing it directly with Athena. However, to get better performance, you can partition the data, compress data, or convert it to columnar formats such as Apache Parquet using AWS Glue. AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and integrate the data into a data lake where it is natively accessed by analytics and machine learning tools such as Athena, SageMaker, and Redshift Spectrum.
After you have your PITR-enabled table and selected a destination Amazon S3 bucket for the data export, you can initiate your first DynamoDB export. For this post, we’ve done that in the new DynamoDB console (available in preview) by navigating to the Exports and streams tab of the table.

Enter your bucket name in the Destination S3 bucket box (in our case, it’s s3://dynamodb-to-s3-export-results, as shown in the following screenshot). You also can specify a bucket that is in another account or AWS Region.

Choosing Additional settings allows you to configure a specific point in time of the restore, the export output format, and the encryption key. For sake of simplicity, we have not changed the additional settings.
Start the export job by choosing Export to S3. After you initiate an export job, you can view the status in the console.

View the dataset in Amazon S3
The time to export a table using the new feature is fast—even for very large tables—when compared to the previous approach of scanning the table to perform an export. You will spend no time deploying infrastructure, and the export time is not necessarily a function of table size because it’s performed in parallel and depends on how uniformly the table data is distributed. In our test, we exported 160 GB of data in 11 minutes. When an export is initiated from DynamoDB, the IAM role that initiates the export job is the same role that writes the data to your Amazon S3 bucket.
When the export process is complete, a new AWSDynamoDB folder is shown in your Amazon S3 bucket with a subfolder corresponding to the export ID.

In our case, we have four manifest objects and a data folder. The manifest objects include the following details from the export:
- manifest-files.json – Lists the names and item counts for each exported data object.
- manifest-summary.json – Provides general information about the exported dataset.
- manifest-files.md5 and manifest-summary.md5 – Are .md5 checksums of the corresponding JSON objects.
The data folder contains the entire dataset saved as .gz files. Now that the data is in Amazon S3, you can use AWS Glue to add the data as a table to the AWS Glue Data Catalog.
Associate exported data with an AWS Glue Data Catalog
AWS Glue is the AWS entry point for ETL and analytics workloads. In the AWS Glue console, you can define a crawler by using the Amazon S3 export location. You must configure the Glue crawler to crawl all objects in s3://<bucket-name>/AWSDynamoDB/<export-id>/data. In this walkthrough, we don’t go deep into how to use AWS Glue crawlers and the Data Catalog. At a high level, crawlers scan the S3 path containing the exported data objects to create table definitions in the Data Catalog that you can use for executing Athena queries or Glue ETL jobs.
After the crawler has been created, the exported data is now associated with a new Data Catalog table.

We can query our table directly by using Athena. For example, our query to count which customer posted the most reviews looks like the following.
The following screenshot shows the results of this query, which include customers (identified by item.customer_id.s) and how many reviews (identified by Count) they have published.

A single customer in this sample data wrote 1,753 reviews. Creating more complex queries is straightforward; grouping by year and product is as simple as expanding the query.
Transform the exported data into Parquet format and partition the data for optimized analytics
For data analytics at scale, you also can use AWS Glue to transform the exported data into higher performing data formats. AWS Glue natively supports many format options for ETL inputs and outputs, including Parquet and Avro, which are commonly used for analytics. Parquet is a column-storage format that provides data compression and encoding that can improve performance of analytics on large datasets. Partitioning data is an important step for organizing data for more efficient analytics queries, reducing cost and query time in the process. The default DynamoDB JSON is not partitioned or formatted for analytics.
Let’s extend our example by using AWS Glue to transform the exported data into Parquet format and partition the data for optimized analytics. The first step is understanding what the data should look like when the ETL job is complete. By default, the data is nested within JSON item structures. We want to flatten the data so that the individual, nested attributes become top-level columns in the analytics table. This enables more efficient partitioning and simpler queries.
We can configure AWS Glue jobs by using a visual builder, but to flatten the nested structure, we need to leverage a transformation called Relationalize. (For a step-by-step walkthrough of this transformation, see Simplify Querying Nested JSON with the AWS Glue Relationalize Transform.) For our purposes in this post, we jump right into the AWS Glue job that transforms and partitions the data as well as the query impact, as shown in the following code example.
Although the structure of this job is similar to the aforementioned method to implement the Relationalize transformation, note the following:
- The code
connection_options = {... "partitionKeys": ["item.year.n"]}specifies how data is partitioned in Amazon S3. The partition key choice is specific to the dataset and the nature of the analytics. For example, if you’re performing queries using time periods,item.year.nis a good choice for partitioning the data. - The code
format = "parquet"sets the AWS Glue job to write the data to Amazon S3 in Parquet format.
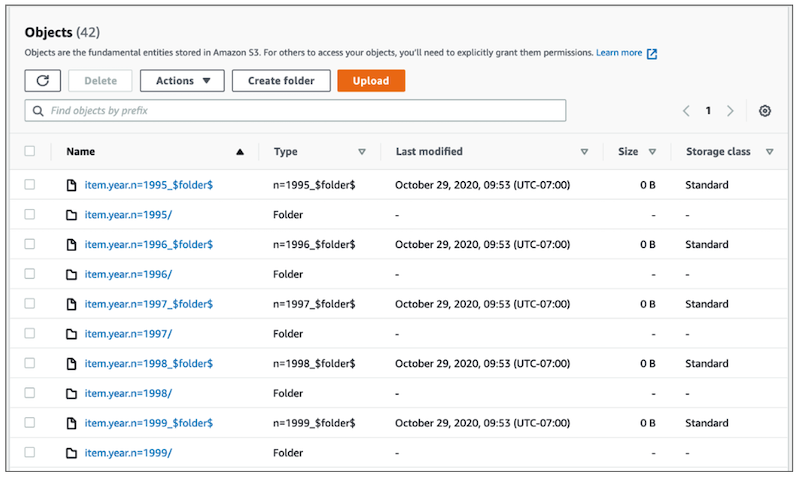
The result of the preceding AWS Glue job is a new set of Parquet files organized by year in Amazon S3 folders.
As a new time-specific query, let’s say we want instead to use Athena to see the first 100 reviews of an item. The following Athena code example shows this query.
The dataset from this example is relatively small, but we can see a significant improvement in the amount of data read while querying. For the sake of comparison, when we performed the earlier AWS Glue job (partitioned by year), we performed a job that exported to Parquet without a partition key. Now, when we use Athena to query the dataset that was not partitioned, we scan 322 MB (the query against the partitioned data scanned only 42 MB). The partitioned data is nearly eight times more efficient, and, because Athena bills by GB scanned, eight times more cost-efficient.
Clean up your resources
After you create an export, view the dataset in Amazon S3, transform the exported data into Parquet format, and use Athena to query and review the results, you should remove any resources that you created in this process. Resources that remain active can incur associated costs.
Conclusion
In this post, we demonstrated how to use the DynamoDB data export to Amazon S3 feature with AWS Glue and Athena to perform analytics at scale by using Apache Parquet. This feature reduces the complexity, infrastructure management, and production impact of making the DynamoDB data easily accessible in Amazon S3, and it also removes the need for additional tools that scan and export the table. Happy exporting and querying!
